

LQRegulatorTrain
LQRegulatorTrain[espec,wts,tspec]
trains the regulator that minimizes the quadratic cost with weights wts for the environment specification espec by simulating it over time specification tspec.
LQRegulatorTrain[espec,wts,g,tspec]
starts with the value g for the regulator gain.
LQRegulatorTrain[…,"prop"]
gives the value of the property "prop".
Details
- LQRegulatorTrain trains the regulator by simulation and is useful when the model of the environment is not available or is varying.
- The regulator is also known as the agent.
- The regulator value starts with a stabilizing gain
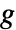 that results in the control action
that results in the control action 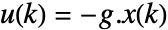 and updates the gain after observing the resulting state values
and updates the gain after observing the resulting state values 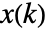 of the environment for the various values
of the environment for the various values 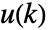 commanded by the regulator.
commanded by the regulator. - The regulator minimizes the quadratic cost
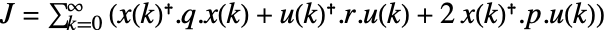 .
. - The regulator is computed by iteratively solving for the
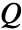 function. The
function. The 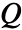 function is also known as the quality function or the action-value function.
function is also known as the quality function or the action-value function. - The
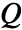 function is given by
function is given by 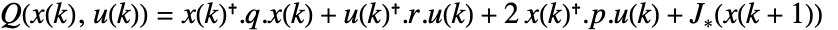 .
. - The
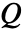 function is the cost for taking action
function is the cost for taking action 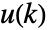 when the environment's state is
when the environment's state is 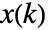 at time instant
at time instant 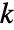 , and from then on taking the optimal action resulting in the optimal cost
, and from then on taking the optimal action resulting in the optimal cost 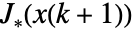 .
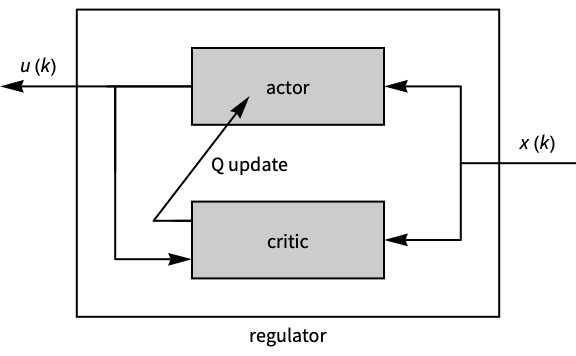
. - The critic in the regulator observes batches of action and state values, computes a better estimate of the Q function, and the actor updates the control action.
- The environment specification espec is the simulation model of the environment together with the x(k) and u(k) specifications.
- The environment specification espec can be specified as a state update function
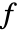 with
with 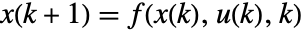 :
: -
f user-defined function Function pure function CompiledFunction compiled function - As library functions that load an external state update function
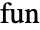 with signature
with signature 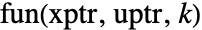 , where
, where 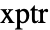 and
and 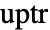 are pointers to
are pointers to 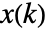 and
and 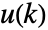 :
: -
LibraryFunction function loaded from a Wolfram library ForeignFunction function loaded from a C library - As models:
-
StateSpaceModel linear control action and linear state AffineStateSpaceModel linear control action and nonlinear state NonlinearStateSpaceModel nonlinear control action and nonlinear state SystemModel general system model - As a device or a more detailed specification:
-
"Device" external device <…> detailed system specification given as an Association - The detailed system specification can have the following keys:
-
"FeedbackInputs" the inputs to use for feedback "InitialStateValues" the initial state values "InputModel" any of environments "InputOperatingValues" operating values of the inputs "PertubationSize" size of the feedback input perturbation "SamplingPeriod" sampling period for devices and continuous-time systems "StateOperatingValues" operating values of the states - The weights wts can have the following forms:
-
{q,r} cost function with no cross-coupling {q,r,p} cost function with cross-coupling matrix p - The time specification tspec can have the following forms:
-
kmax number of simulations {b,kmax} specify the batch length b as well - The batch length b specifies the number of simulations after which the control action is updated.
- LQRegulatorTrain[…, "Data"] returns a SystemsModelControllerData object cd that can be used to extract additional properties using the form cd["prop"].
- LQRegulatorTrain[…, "prop"] can be used to directly give the value of cd["prop"].
- Possible values for properties "prop" include:
-
"BatchLength" number of iterations before the gain is updated "ConvergedQ" whether the gain values have converged "Design" type of controller design "FeedbackGains" final gain matrix "FeedbackGainsSequence" sequence of gain matrices "FeedbackInputs" inputs used for feedback "FeedbackInputsSequence" applied feedback input sequence "InputCount" number of inputs "InputModel" input model "KernelMatrix" kernel matrix of the Q function "SamplingPeriod" sampling period "SimulationRange" simulation range "StateCount" number of states "StateResponse" state response
Examples
open all close allBasic Examples (1)
espec = <|"InputModel" -> (0.55#1 + 1.5 #2&), "InitialStateValues" -> {5}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 20]ListStepPlot[cd["StateResponse"], IconizedObject[«opts»]]ListStepPlot[Flatten[cd["FeedbackGainsSequence"], 1], IconizedObject[«opts»]]Scope (16)
Environments (11)
An environment specified as a function:
env[x_, u_, k_] := x + uThe complete environment specification:
espec = <|"InputModel" -> env, "InitialStateValues" -> {1}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 30]ListStepPlot[cd["StateResponse"], PlotRange -> All, DataRange -> cd["SimulationRange"]]env[x_, u_, k_] := (| | |
| ----- | ---- |
| -0.75 | -0.2 |
| 0.5 | 0 |).x + (| |
| -- |
| 1 |
| -1 |).uespec = <|"InputModel" -> env, "InitialStateValues" -> {-0.1, 0.1}|>;cd = LQRegulatorTrain[espec, {IdentityMatrix[2], {{2}}}, 25]ListStepPlot[cd["StateResponse"], PlotRange -> {{0, 12}, All}, DataRange -> cd["SimulationRange"]]An environment specified using a pure function:
env = Function[{x, u, k}, (| | |
| ---- | --- |
| 0.3 | 0.1 |
| -0.4 | 0 |).x + (| |
| -- |
| 1 |
| -1 |).u]espec = <|"InputModel" -> env, "InitialStateValues" -> {1, -1}|>;cd = LQRegulatorTrain[espec, {IdentityMatrix[2], {{2}}}, 50]ListStepPlot[cd["StateResponse"], PlotRange -> {{0, 10}, All}, DataRange -> cd["SimulationRange"]]An environment specified using a compiled function:
env = Compile[{{x, _Real, 1}, {u, _Real, 1}, k}, (| | |
| ---- | --- |
| 0.3 | 0.1 |
| -0.4 | 0 |).x + (| |
| -- |
| 1 |
| -1 |).u]espec = <|"InputModel" -> env, "InitialStateValues" -> {1.0, -1.0}|>;cd = LQRegulatorTrain[espec, {IdentityMatrix[2], {{2}}}, 50]ListStepPlot[cd["StateResponse"], PlotRange -> {{0, 10}, All}, DataRange -> cd["SimulationRange"]]Create a library function to provide the environment:
Needs["SymbolicC`"]
Needs["CCompilerDriver`"]model = ToCCodeString[IconizedObject[«model»]]modelWrapper = ToCCodeString[IconizedObject[«modelwrapper»]]Compile the code and create a library:
modelObj = CreateObjectFile[model, "model", "TargetDirectory" -> $TemporaryDirectory]modelWrapperObj = CreateObjectFile[modelWrapper, "modelwrapper", "TargetDirectory" -> $TemporaryDirectory]modelLib = CreateLibrary[{modelObj, modelWrapperObj}, "modelLib", "TargetDirectory" -> $TemporaryDirectory]Load the function in the library:
env = LibraryFunctionLoad[modelLib, "model_wrapper", {{Real, 1, "Shared"}, {Real, 1, "Shared"}, Integer}, "Void"]The complete environment specification:
espec = <|"InputModel" -> env, "InitialStateValues" -> {1.0}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 35]ListStepPlot[cd["StateResponse"], PlotRange -> {{0, 20}, All}, DataRange -> cd["SimulationRange"]]Create a foreign function to provide the environment:
Needs["SymbolicC`"]
Needs["CCompilerDriver`"]code = ToCCodeString[SymbolicC`CFunction[...]]Compile the code and create a library:
modelLib = CreateLibrary[code, "modelLib", "TargetDirectory" -> $TemporaryDirectory]Load the function in the library:
env = ForeignFunctionLoad[modelLib, "model", {"RawPointer"::["CDouble"], "RawPointer"::["CDouble"], "CInt"} -> "Void"]The complete environment specification:
espec = <|"InputModel" -> env, "InitialStateValues" -> {2.0}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 20]ListStepPlot[cd["StateResponse"], PlotRange -> {{0, 10}, All}, DataRange -> cd["SimulationRange"]]An environment with nonzero operating points:
espec = <|"InputModel" -> (-0.85(#1 - 1) - 1.5 (#2 - 0.5)&), "StateOperatingValues" -> {1}, "InputOperatingValues" -> {0.5}, "InitialStateValues" -> {5}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 30]The state settles at its operating value of 1:
Show[ListStepPlot[cd["StateResponse"], PlotRange -> All, DataRange -> cd["SimulationRange"]], Plot[1, {$, 0, 30}, IconizedObject[«opts»]]]The input settles at its operating value of 0.5:
ListStepPlot[cd["FeedbackInputsSequence"], PlotRange -> All, DataRange -> cd["SimulationRange"]]An environment specified using a state-space model:
espec = <|"InputModel" -> StateSpaceModel[{{{0.6}}, {{2}}}, SamplingPeriod -> 1], "InitialStateValues" -> {1}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 20]ListStepPlot[cd["StateResponse"], DataRange -> cd["SimulationRange"], PlotRange -> All]An environment specified using a nonlinear state-space model:
espec = <|"InputModel" -> NonlinearStateSpaceModel[{{u + 0.1*x + Sin[x]}, {x}}, x, u, SamplingPeriod -> 1], "InitialStateValues" -> {1}|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, {{1}}, 20]ListStepPlot[cd["StateResponse"], DataRange -> cd["SimulationRange"], PlotRange -> All]An environment specified using a system model:
espec = <|"InputModel" -> CreateSystemModel["env", StateSpaceModel[{{{-1}}, {{1}}}]], "InitialStateValues" -> {1}, "SamplingPeriod" -> 0.01|>cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 250]ListStepPlot[cd["StateResponse"], PlotRange -> All, DataRange -> 0.01 cd["SimulationRange"]]Create an environment on a microcontroller:
Needs["MicrocontrollerKit`"]MicrocontrollerEmbedCode[IconizedObject[«sys»], IconizedObject[«μc»], "/dev/ttyACM0"]The environment specification:
espec = <|"InputModel" -> "Device", "Connection" -> "Serial", "Port" -> "/dev/ttyACM0", "SamplingPeriod" -> 0.75|>;cd = LQRegulatorTrain[espec, {{{1}}, {{1}}}, 40]ListStepPlot[cd["StateResponse"], PlotRange -> All, DataRange -> cd["SimulationRange"]]Properties (5)
LQRegulatorTrain returns a SystemsModelControllerData object:
LQRegulatorTrain[<|"InputModel" -> (0.1 #1 + #2&), "InitialStateValues" -> {1}|>, {{{1}}, {{1}}}, 15]The data object can be used to obtain additional properties:
SystemsModelControllerData[Association["SummaryItemsFunction" -> Control`RLDump`iQLLQRSummaryItems,
"PropertyFunction" -> Control`RLDump`iQLLQRProperty, "FeedbackGains" -> {{0.05012499921757796}},
"FeedbackGainsValues" -> {{{0, 0.050251256281 ... nsValues",
"StateValues", "FeedbackInputValues", "StateCount", "InputCount", "BatchLength",
"SimulationRange", "KernelMatrix", "ConvergedQ", "Design", "SimulationModel", "SamplingPeriod",
"InputModel", "FeedbackInputs", "TrackedOutputs"}]["FeedbackInputValues"]SystemsModelControllerData[Association["SummaryItemsFunction" -> Control`RLDump`iQLLQRSummaryItems,
"PropertyFunction" -> Control`RLDump`iQLLQRProperty, "FeedbackGains" -> {{0.05012499921757796}},
"FeedbackGainsValues" -> {{{0, 0.050251256281 ... nsValues",
"StateValues", "FeedbackInputValues", "StateCount", "InputCount", "BatchLength",
"SimulationRange", "KernelMatrix", "ConvergedQ", "Design", "SimulationModel", "SamplingPeriod",
"InputModel", "FeedbackInputs", "TrackedOutputs"}]["BatchLength"]SystemsModelControllerData[Association["SummaryItemsFunction" -> Control`RLDump`iQLLQRSummaryItems,
"PropertyFunction" -> Control`RLDump`iQLLQRProperty, "FeedbackGains" -> {{0.05012499921757796}},
"FeedbackGainsValues" -> {{{0, 0.050251256281 ... nsValues",
"StateValues", "FeedbackInputValues", "StateCount", "InputCount", "BatchLength",
"SimulationRange", "KernelMatrix", "ConvergedQ", "Design", "SimulationModel", "SamplingPeriod",
"InputModel", "FeedbackInputs", "TrackedOutputs"}][{"FeedbackGains", "SimulationRange", "SimulationModel"}]SystemsModelControllerData[Association["SummaryItemsFunction" -> Control`RLDump`iQLLQRSummaryItems,
"PropertyFunction" -> Control`RLDump`iQLLQRProperty, "FeedbackGains" -> {{0.05012499921757796}},
"FeedbackGainsValues" -> {{{0, 0.050251256281 ... nsValues",
"StateValues", "FeedbackInputValues", "StateCount", "InputCount", "BatchLength",
"SimulationRange", "KernelMatrix", "ConvergedQ", "Design", "SimulationModel", "SamplingPeriod",
"InputModel", "FeedbackInputs", "TrackedOutputs"}]["PropertyDataset"]LQRegulatorTrain[<|"InputModel" -> (0.1 #1 + #2&), "InitialStateValues" -> {1}|>, {{{1}}, {{1}}}, 15, "FeedbackGains"]Applications (1)
Chemical Systems (1)
Train an agent to regulate a CSTR decomposition process:
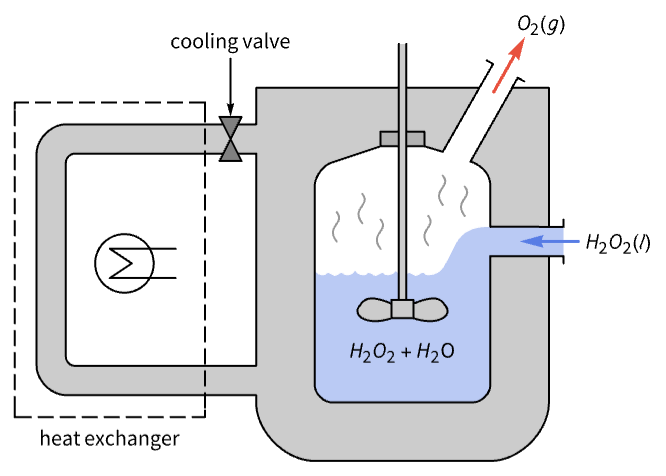
A simulation model of the CSTR:
IconizedObject[«CSTR»]Create a library from the simulation model:
Needs["CCompilerDriver`"]cstrLib = CreateLibrary[IconizedObject[«CSTR»], "cstrLib", "TargetDirectory" -> $TemporaryDirectory]The environment specification:
espec = <|"InputModel" -> ForeignFunctionLoad[cstrLib, "update_cstr", {"RawPointer"::["CDouble"], "RawPointer"::["CDouble"], "CInt"} -> "Void"], "InitialStateValues" -> {0, -1}|>cd = LQRegulatorTrain[espec, wts = {(| | |
| ---- | ---- |
| 10^3 | 0 |
| 0 | 10^3 |), (1)}, {{1, -1}}, 200]p1 = Table[ListStepPlot[sr, PlotRange -> All, DataRange -> {0, (200 - 1)}0.1], {sr, cd["StateResponse"]}];
GraphicsRow[p1]The closed-loop system with the regulator computed using an explicit model:
csys = LQRegulatorGains[IconizedObject[«ssm»], wts, "ClosedLoopSystem"]Compare the simulation- and model-based state responses:
p2 = Table[Plot[sr, {t, 0, 20}, PlotRange -> All, PlotStyle -> ColorData[116, 2]], {sr, StateResponse[{csys, {0, -1}}, {0, 0}, {t, 0, 20}]}];Legended[GraphicsRow[{Show[p1[[1]], p2[[1]]], Show[p1[[2]], p2[[2]]]}], IconizedObject[«leg»]]Properties & Relations (2)
The gains typically converge to the optimal regulator gains:
espec = <|"InputModel" -> Function[{x, u, k}, 0.7x + 0.5 u ], "InitialStateValues" -> {RandomReal[{-1, 1}]}|>;κlist = LQRegulatorTrain[espec, IconizedObject[«wts»], 30, "FeedbackGainsSequence"]StateSpaceModel[Thread[{x[k + 1]} == espec["InputModel"][{x[k]}, {u[k]}, k]], x[k], u[k], x[k], k]κ = LQRegulatorGains[%, IconizedObject[«wts»]]Compare the iteratively computed gain and the optimal gain:
Show[ListStepPlot[Flatten[κlist, 1], IconizedObject[«opts»]], Plot[κ, {$, 0, 30}, IconizedObject[«opts»]]]The Q function can be computed from the kernel matrix:
{a, b} = {{{0.4}}, {{1}}};
{q, r} = {{{1}}, {{1}}};cd = LQRegulatorTrain[<|"InputModel" -> StateSpaceModel[{a, b}, SamplingPeriod -> 1], "InitialStateValues" -> {RandomReal[{-1, 1}]}|>, {q, r}, 20]Q = {x, u}.cd["KernelMatrix"].{x, u}//ExpandQ /. Thread[{u} -> -cd["FeedbackGains"].{x}]The same result can be obtained using DiscreteRiccatiSolve:
{x}.DiscreteRiccatiSolve[{a, b}, {q, r}].{x}Possible Issues (2)
The initial gain must be stabilizing, otherwise the state response will blow up:
espec = <|"InputModel" -> Function[{x, u, k}, -0.9x + 2 u ], "InitialStateValues" -> {RandomReal[{-1, 1}]}|>;LQRegulatorTrain[espec, IconizedObject[«wts»], {{2}}, IconizedObject[«tspec»], "StateResponse"]The state response with a stabilizing gain:
LQRegulatorTrain[espec, IconizedObject[«wts»], {{0.1}}, IconizedObject[«tspec»], "StateResponse"]The regulator may not converge to the optimal solution:
espec = <|"InputModel" -> Function[{x, u, k}, 3 x + u], "InitialStateValues" -> {RandomReal[{-2, 2}]}|>;LQRegulatorTrain[espec, IconizedObject[«wts»], IconizedObject[«tspec»], {"FeedbackGains", "ConvergedQ"}]LQRegulatorGains[StateSpaceModel[{{{3}}, {{1}}}, SamplingPeriod -> 1], IconizedObject[«wts»]]//NTry adjusting the initial gain:
LQRegulatorTrain[espec, IconizedObject[«wts»], {{5}}, IconizedObject[«tspec»], {"FeedbackGains", "ConvergedQ"}]Text
Wolfram Research (2026), LQRegulatorTrain, Wolfram Language function, https://reference.wolfram.com/language/ref/LQRegulatorTrain.html.
CMS
Wolfram Language. 2026. "LQRegulatorTrain." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/LQRegulatorTrain.html.
APA
Wolfram Language. (2026). LQRegulatorTrain. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/LQRegulatorTrain.html