



EstimatedDistribution
EstimatedDistribution[data,dist]
estimates the parametric distribution dist from data.
EstimatedDistribution[data,dist,{{p,p0},{q,q0},…}]
estimates the parameters p, q, … with starting values p0, q0, ….
EstimatedDistribution[data,dist,idist]
estimates distribution dist with starting values taken from the instantiated distribution idist.
Details and Options
- EstimatedDistribution returns the distribution dist with parameter estimates inserted for any non-numeric values.
- The data must be a list of possible outcomes from the given distribution dist.
- The distribution dist can be any parametric univariate, multivariate, or derived distribution with unknown parameters.
- The following options can be given:
-
AccuracyGoal Automatic the accuracy sought ParameterEstimator "MaximumLikelihood" what parameter estimator to use PrecisionGoal Automatic the precision sought WorkingPrecision Automatic the precision used in internal computations - The following basic settings can be used for ParameterEstimator:
-
"MaximumLikelihood" maximize the log‐likelihood function "MethodOfMoments" match raw moments "MethodOfCentralMoments" match central moments "MethodOfCumulants" match cumulants "MethodOfFactorialMoments" match factorial moments - The maximum likelihood method attempts to maximize the log-likelihood function
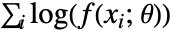 , where
, where 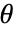 are the distribution parameters and
are the distribution parameters and 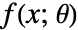 is the PDF of the distribution.
is the PDF of the distribution. - The method of moments solves
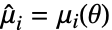 ,
, 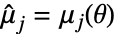 ,
,  , where
, where 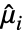 is the
is the 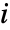
") sample moment and
sample moment and 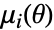 is the
is the 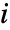
") moment of the distribution, with parameters
moment of the distribution, with parameters 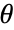 .
. - Method-of-moment-based estimators may not satisfy all restrictions on parameters.
Examples
open all close allBasic Examples (3)
Obtain the maximum likelihood parameter estimates, assuming a gamma distribution:
data = RandomVariate[𝒟 = GammaDistribution[1, 2], 10 ^ 3];e𝒟 = EstimatedDistribution[data, GammaDistribution[α, β]]Visually compare the PDFs for the original and estimated distributions:
Plot[{PDF[𝒟, x], PDF[e𝒟, x]}, {x, 0, 10}, PlotLegends -> {"𝒟", "e𝒟"}]Obtain the method of moments estimates:
EstimatedDistribution[data, GammaDistribution[α, β], ParameterEstimator -> "MethodOfMoments"]Estimate parameters for a multivariate distribution:
data = RandomVariate[MultivariatePoissonDistribution[5, {4, 3, 10}], 20];EstimatedDistribution[data, MultivariatePoissonDistribution[μ, {Subscript[μ, 1], Subscript[μ, 2], Subscript[μ, 3]}]]Estimated parameters from data with quantities:
data = RandomVariate[NormalDistribution[Quantity[200, "Centimeters"], Quantity[7, "Centimeters"]], 20]EstimatedDistribution[data, NormalDistribution[m, s]]Scope (15)
Basic Uses (5)
Estimate both parameters for a binomial distribution:
bdata = {23, 16, 24, 17, 16, 17, 18, 17, 19, 23, 19, 13, 19, 18, 22, 21, 19, 22, 19, 23};EstimatedDistribution[bdata, BinomialDistribution[n, p]]Estimate p, assuming n is known:
EstimatedDistribution[bdata, BinomialDistribution[50, p]]Estimate n, assuming p is known:
EstimatedDistribution[bdata, BinomialDistribution[n, 2 / 5]]Get the distribution with maximum likelihood parameter estimate for a particular family:
vals = RandomReal[ChiSquareDistribution[20], 1000];dist = EstimatedDistribution[vals, ChiSquareDistribution[n]]Check goodness of fit by comparing a histogram of the data and the estimate's PDF:
Show[Histogram[vals, Automatic, "ProbabilityDensity"], Plot[PDF[dist, x], {x, 0, 50}]]Perform goodness-of-fit tests with null distribution dist:
DistributionFitTest[vals, dist, {"TestDataTable", All}]Perform tests correcting for estimation of the parameter:
DistributionFitTest[vals, ChiSquareDistribution[n], {"TestDataTable", All}]Estimate parameters by maximizing the log‐likelihood:
data = RandomVariate[GeometricDistribution[.4], 100];dist = EstimatedDistribution[data, GeometricDistribution[p]]phat = dist[[1]]Plot the log‐likelihood function to visually check that the solution is optimal:
Show[Plot[LogLikelihood[GeometricDistribution[p], data], {p, 0, 1}], Graphics[{PointSize[Large], Red, Point[{phat, LogLikelihood[GeometricDistribution[phat], data]}]}]]Visualize a log‐likelihood surface to find rough values for the parameters:
data = BlockRandom[SeedRandom[100];RandomVariate[WeibullDistribution[4, 5], 50]];ContourPlot[LogLikelihood[WeibullDistribution[α, β], data], {α, 2, 6}, {β, 3, 8}]Supply those rough values as starting values for the estimation:
EstimatedDistribution[data, WeibullDistribution[α, β], WeibullDistribution[3, 5.5]]Estimate the normal approximation of Poisson data:
data = RandomVariate[PoissonDistribution[20], 100];EstimatedDistribution[data, NormalDistribution[μ, σ]]Obtain the estimate to 20 digits:
EstimatedDistribution[data, NormalDistribution[μ, σ], WorkingPrecision -> 20]Univariate Parametric Distributions (2)
Estimate parameters for a continuous distribution:
data = {0.8, 0.98, 0.66, 0.09, 0.03, 0.16, 0.88, 0.32, 0.56, 0.3, 0.82, 0.34, 0.93, 0.33, 0.25, 0.74, 0.3, 0.74, 0.16, 0.02};EstimatedDistribution[data, BetaDistribution[α, β]]Compare empirical and distribution quantiles:
QuantilePlot[data, %]Estimate parameters for a discrete distribution:
data = {16, 1, 2, 5, 3, 5, 1, 6, 4, 14, 2, 9, 1, 1, 2, 2, 8, 1, 3, 1};EstimatedDistribution[data, LogSeriesDistribution[θ]]Multivariate Parametric Distributions (2)
Estimate parameters for a discrete multivariate distribution:
mdata = RandomVariate[MultinomialDistribution[20, {1 / 3, 1 / 6, 1 / 10, 2 / 5}], 1000];EstimatedDistribution[mdata, MultinomialDistribution[n, {Subscript[p, 1], Subscript[p, 2], Subscript[p, 3], Subscript[p, 4]}]]Estimate parameters for a continuous multivariate distribution:
bndata = RandomVariate[BinormalDistribution[{1, 2}, {1 / 3, 4}, 3 / 4], 1000];dist = EstimatedDistribution[bndata, BinormalDistribution[{Subscript[μ, 1], Subscript[μ, 2]}, {Subscript[σ, 1], Subscript[σ, 2]}, ρ]]Compare the difference between the original and estimated PDFs:
Plot3D[PDF[BinormalDistribution[{1, 2}, {1 / 3, 4}, 3 / 4], {x, y}] - PDF[dist, {x, y}], {x, 0, 2}, {y, -10, 16}, PlotRange -> All]Derived Distributions (6)
Estimate parameters for a truncated normal:
𝒟o = TruncatedDistribution[{-1, 2}, NormalDistribution[1, 1 / 3]];SeedRandom[1];
data = RandomVariate[𝒟o, 100];𝒟e = EstimatedDistribution[data, TruncatedDistribution[{-1, 2}, NormalDistribution[μ, σ]]]Compare original and estimated distribution:
Plot[{PDF[𝒟o, x], PDF[𝒟e, x]}, {x, -1, 3}, Filling -> Axis, PlotLegends -> {"𝒟o", "𝒟e"}]Estimate parameters for a constructed distribution:
dist = ProbabilityDistribution[λ Exp[λ(1 - x)], {x, 1, Infinity}, Assumptions -> λ > 0]EstimatedDistribution[{1.4, 5.1, 1.7, 1.6, 1.1, 3.9, 2.2, 1.3, 2., 1.5}, dist]Estimate parameters for a product distribution:
data = RandomVariate[ProductDistribution[BetaDistribution[2, 3], LaplaceDistribution[10, 1]], 100];EstimatedDistribution[data, ProductDistribution[BetaDistribution[α, β], LaplaceDistribution[μ, σ]]]Estimate parameters for a copula distribution:
𝒟o = CopulaDistribution[{"Frank", 1 / 2}, {GammaDistribution[2, 3], ChiSquareDistribution[10]}];data = RandomVariate[𝒟o, 100];𝒟e = EstimatedDistribution[data, CopulaDistribution[{"Frank", c}, {GammaDistribution[α, β], ChiSquareDistribution[n]}]]Compare original and estimated CDFs:
Plot3D[CDF[𝒟o, {x, y}] - CDF[𝒟e, {x, y}], {x, 0, 25}, {y, 0, 35}, PlotRange -> All]Estimate parameters for a component mixture:
data = RandomVariate[MixtureDistribution[{1 / 3, 2 / 3}, {GammaDistribution[2, 3], NormalDistribution[1, 1 / 4]}], 100];EstimatedDistribution[data, MixtureDistribution[{p, 1 - p}, {GammaDistribution[α, β], NormalDistribution[μ, σ]}]]//QuietEstimate the mixture probabilities assuming the component distributions are known:
EstimatedDistribution[data, MixtureDistribution[{p, 1 - p}, {GammaDistribution[2, 3], NormalDistribution[1, 1 / 4]}]]//QuietEstimate parameters for quantity distribution in specified units:
data = RandomVariate[NormalDistribution[Quantity[200, "Centimeters"], Quantity[7, "Centimeters"]], 100]EstimatedDistribution[data, QuantityDistribution[NormalDistribution[m, s], "Meters"]]Options (4)
ParameterEstimator (3)
Estimate parameters by matching central moments:
data = RandomVariate[ParetoDistribution[2, 8, 5], 1000];EstimatedDistribution[data, ParetoDistribution[α, β, μ], ParameterEstimator -> "MethodOfCentralMoments"]Other moment‐based methods typically give similar results:
EstimatedDistribution[data, ParetoDistribution[α, β, μ], ParameterEstimator -> "MethodOfCentralMoments"]EstimatedDistribution[data, ParetoDistribution[α, β, μ], ParameterEstimator -> "MethodOfFactorialMoments"]Estimate parameters based on default moments:
data = RandomVariate[NormalDistribution[2, 3], 1000];EstimatedDistribution[data, NormalDistribution[μ, σ], ParameterEstimator -> "MethodOfMoments"]Estimate parameters from the first and fourth moments:
EstimatedDistribution[data, NormalDistribution[μ, σ], ParameterEstimator -> {"MethodOfMoments", "MomentOrders" -> {1, 4}}]Obtain the maximum likelihood estimates using the default method:
data = RandomVariate[BetaDistribution[2, 3], 1000];EstimatedDistribution[data, BetaDistribution[α, β]]Use FindMaximum to obtain the estimates:
EstimatedDistribution[data, BetaDistribution[α, β], ParameterEstimator -> {"MaximumLikelihood", Method -> "FindMaximum"}]Use EvaluationMonitor to extract the points sampled:
{params, {points}} = Reap[EstimatedDistribution[data, BetaDistribution[α, β], ParameterEstimator -> {"MaximumLikelihood", Method -> {"FindMaximum", EvaluationMonitor :> Sow[{α, β}]}}]];Visualize the sequences of sampled ![]() and
and ![]() values:
values:
ListLogPlot[Transpose[points], PlotLegends -> {"α", "β"}]WorkingPrecision (1)
Use machine precision for continuous parameters by default:
data = RandomVariate[GumbelDistribution[2, 5], 100, WorkingPrecision -> 50];EstimatedDistribution[data, GumbelDistribution[α, β]]Obtain a higher-precision result:
EstimatedDistribution[data, GumbelDistribution[α, β], WorkingPrecision -> 25]Applications (14)
Estimation of Similarly Shaped Distributions (1)
Model lognormal distributed data with a gamma distribution:
lnorm = LogNormalDistribution[2, 0.3];sample = RandomVariate[lnorm, 10 ^ 4];edist = EstimatedDistribution[sample, GammaDistribution[α, β]]Show[Histogram[sample, 20, "ProbabilityDensity"], Plot[PDF[edist, x], {x, 0, 20}, PlotStyle -> Thick]]Compare the distributions of the simulation and estimated distributions:
Plot[{PDF[lnorm, x], PDF[edist, x]}, {x, 0, 25}]Accident Claims (1)
The number of accident claims per policy per year from an insurance company:
accidentsPerPolicyCounts = {81714, 11306, 1618, 250, 40, 7};;accidentsPerPolicy = WeightedData[Range[0, 5], accidentsPerPolicyCounts]Model the data by a logarithmic series distribution since most policies have at most one claim:
edist = EstimatedDistribution[WeightedData[Range[0, 5] + 1, accidentsPerPolicyCounts], LogSeriesDistribution[θ]]Show[Histogram[accidentsPerPolicy, {-0.5, 5.5, 1}, "PDF"], DiscretePlot[PDF[edist, x + 1], {x, 0, 5}, PlotStyle -> PointSize[Medium]]]Word Lengths in Different Languages (1)
Get word length data for several languages:
languages = {"Arabic", "English", "Finnish", "French", "Hebrew", "Hindi", "Italian", "Russian", "Spanish"};worddata = Table[StringLength /@ DictionaryLookup[{l, All}], {l, languages}];Model the word lengths for each language as binomially distributed:
binom = Table[EstimatedDistribution[i, BinomialDistribution[n, p], ParameterEstimator -> {"MaximumLikelihood", Method -> {"FindRoot", MaxIterations -> 1000}}], {i, worddata}]Compare the actual and estimated distributions:
Partition[Table[Show[Histogram[worddata[[i]], {Range[25] - 1 / 2}, "ProbabilityDensity", PlotLabel -> languages[[i]]], DiscretePlot[PDF[binom[[i]], x], {x, 0, 25}, PlotRange -> All, PlotStyle -> PointSize[.025]]], {i, Length[languages]}], 3]//GridText Frequency (1)
The word count in a text follows a Zipf distribution:
text = ExampleData[{"Text", "OriginOfSpecies"}, "Words"];wordCount = Tally[text][[All, 2]];Fit a ZipfDistribution to the word frequency data:
edist = EstimatedDistribution[wordCount, ZipfDistribution[ρ]]Compare the frequency histogram with the estimated distribution:
Show[Histogram[wordCount, {0.5, 20.5, 1}, "ProbabilityDensity"], DiscretePlot[PDF[edist, x], {x, 0, 20}, PlotStyle -> PointSize[Medium]]]Earthquake Magnitudes (1)
EstimatedDistribution can be used with constructs like MixtureDistribution to create multimodal models:
magnitudes = Select[ExampleData[{"Statistics", "USEarthquakes"}], #[[1]] ≥ 1935&][[All, 7]];The magnitudes of earthquakes in the United States in the selected years have two modes:
h = Histogram[magnitudes, 20, "ProbabilityDensity"]Fit distribution from possible mixtures of one NormalDistribution with another:
edist = EstimatedDistribution[magnitudes, MixtureDistribution[{p, 1 - p}, {NormalDistribution[a, b], NormalDistribution[c, d]}]]//QuietCompare the histogram to the PDF of the estimated distribution:
Show[h, Plot[PDF[edist, x], {x, 0, 10}, PlotStyle -> Thick, PlotRange -> All]]Find the probability of an earthquake of magnitude 7 or higher:
Probability[x ≥ 7, xedist]Find the mean earthquake magnitude:
Mean[edist]Simulate magnitudes of the next 30 earthquakes:
ListPlot[RandomVariate[edist, 30], Filling -> Axis]Wind Speed Analysis (1)
Model monthly maximum wind speeds in Boston:
maxWinds = WeatherData["Boston", "MaxWindSpeed", {{1950, 1, 1}, {2009, 12, 31}, "Month"}, "Value"]//QuantityMagnitude;Fit the data to a RayleighDistribution:
edist1 = EstimatedDistribution[maxWinds, RayleighDistribution[θ]]edist2 = EstimatedDistribution[maxWinds, ExtremeValueDistribution[a, b]]Compare the empirical quantiles and those for the fitted distributions to see where the models deviate from the data:
Row[Table[QuantilePlot[maxWinds, i, PlotLabel -> Head[i]], {i, {edist1, edist2}}]]Distribution of Incomes (1)
Model incomes at a large state university:
ExampleData[{"Statistics", "UniversitySalaries"}, "ColumnDescriptions"]universityA = Cases[ExampleData[{"Statistics", "UniversitySalaries"}], {dept_, perc_, salary_, campus : "A"} :> {perc, salary}];salaries = Cases[universityA, {p_ ? Positive, s_ ? Positive} :> s / p];Assume the salaries are Dagum distributed:
edist = EstimatedDistribution[salaries, DagumDistribution[p, a, b]]Assume they follow a more general Pareto distribution:
edist2 = EstimatedDistribution[salaries, ParetoDistribution[k, α, γ, μ], ParameterEstimator -> {"MaximumLikelihood", "Method" -> "SimulatedAnnealing"}]Compare the subtle differences in the estimated distributions:
Show[Histogram[salaries, {0, 200000, 10000}, "PDF"], Plot[{PDF[edist, x], PDF[edist2, x]}, {x, 0, 200000}, PlotStyle -> Thick, PlotLegends -> {DagumDistribution, ParetoDistribution}]]Automobile Fuel Efficiency (1)
The average city and highway mileage for midsize cars follows a binormal distribution:
midsizeMPG2009 = {{16, 22}, {18, 26}, {17, 25}, {16, 23}, {16, 23}, {14, 19}, {13, 19}, {10, 14}, {10, 17}, {18, 28}, {18, 27}, {17, 25}, {17, 25}, {17, 26}, {17, 26}, {16, 25}, {17, 25}, {15, 22}, {15, 23}, {11, 17}, {11, 17}, {17, 28}, {16, 24}, {16, 25}, {16, 25}, {17, 26}, {18, 26}, {17, 26}, {17, 25}, {17, 26}, {13, 19}, {15, 24}, {17, 26}, {15, 22}, {22, 33}, {22, 30}, {18, 29}, {17, 26}, {26, 34}, {21, 30}, {13, 20}, {19, 27}, {16, 27}, {21, 30}, {13, 20}, {19, 27}, {16, 27}, {24, 30}, {23, 27}, {23, 29}, {21, 25}, {19, 27}, {10, 15}, {9, 16}, {17, 25}, {20, 29}, {20, 28}, {18, 26}, {24, 33}, {25, 33}, {16, 25}, {15, 23}, {22, 32}, {22, 32}, {20, 28}, {23, 30}, {24, 32}, {19, 27}, {19, 26}, {18, 25}, {17, 24}, {16, 24}, {16, 23}, {16, 24}, {16, 23}, {20, 22}, {17, 25}, {20, 29}, {20, 28}, {18, 26}, {17, 24}, {18, 28}, {20, 29}, {21, 30}, {17, 25}, {18, 25}, {23, 32}, {17, 24}, {16, 22}, {15, 22}, {13, 19}, {13, 20}, {20, 27}, {16, 25}, {23, 32}, {23, 31}, {18, 27}, {19, 26}, {35, 33}, {19, 26}, {24, 30}, {21, 29}, {26, 31}, {27, 33}, {24, 32}, {11, 18}, {24, 30}, {24, 32}, {22, 33}, {17, 26}, {26, 34}, {21, 31}, {21, 31}, {19, 28}, {33, 34}, {48, 45}, {19, 29}, {15, 23}, {15, 22}, {16, 25}};Assume city and highway miles per gallon are normally distributed and correlated:
edist = EstimatedDistribution[midsizeMPG2009, BinormalDistribution[{μ1, μ2}, {σ1, σ2}, ρ]]Show the distribution of city and highway mileage:
Plot[Evaluate[PDF[MarginalDistribution[edist, #], x]& /@ {1, 2}], {x, 5, 40}, Filling -> Axis, PlotLegends -> {"city", "highway"}]Visualize the joint density with contours on a logarithmic scale:
ContourPlot[Log[PDF[edist, {x, y}]], {x, 0, 50}, {y, 0, 50}, Contours -> 50]Earthquake Waiting Times (1)
The data contains waiting times in days between serious (magnitude at least 7.5 or over 1000 fatalities) earthquakes worldwide, recorded from 12/16/1902 to 3/4/1977:
earthquakesWaitingTimes = ExampleData[{"Statistics", "EarthquakeWaitingTimes"}];Model waiting times by an ExponentialDistribution:
edist = EstimatedDistribution[earthquakesWaitingTimes, ExponentialDistribution[λ]]Estimate the average and median number of days between major earthquakes:
{Mean[edist], Median[edist]}Earthquake Frequency (1)
The number of earthquakes per year can be modeled by SinghMaddalaDistribution:
ExampleData[{"Statistics", "USEarthquakes"}, "ColumnDescriptions"]earthquakes = Tally[Select[ExampleData[{"Statistics", "USEarthquakes"}], #[[1]] ≥ 1935&][[All, 1]]][[All, 2]]Fit the distribution to the data:
edist = EstimatedDistribution[earthquakes, SinghMaddalaDistribution[q, a, b]]Compare the data histogram with the PDF of the estimated distribution:
Show[Histogram[earthquakes, 15, "ProbabilityDensity"], Plot[PDF[edist, x], {x, 0, 140}, PlotStyle -> Thick]]Find the probability of at least 60 earthquakes in the US in a year:
NProbability[x ≥ 60, xedist]Time between Geyser Eruptions (1)
Mixtures can be used to model multimodal data:
ExampleData[{"Statistics", "OldFaithful"}, "ColumnDescriptions"]waiting = ExampleData[{"Statistics", "OldFaithful"}][[All, 2]];A histogram of waiting times for eruptions of the Old Faithful geyser exhibits two modes:
h = Histogram[waiting, 20, "ProbabilityDensity"]Fit a MixtureDistribution to the data:
mdist = MixtureDistribution[{1 / 3, 2 / 3}, {GammaDistribution[a, b], GammaDistribution[c, d]}];edist = Quiet@EstimatedDistribution[waiting, mdist, {{a, 85}, {b, .5}, {c, 195}, {d, .4}}]Compare the histogram to the PDF of the estimated distribution:
Show[h, Plot[PDF[edist, x], {x, 0, 100}, PlotStyle -> Thick]]Find the probability that the waiting time is over 80 minutes:
NProbability[x > 80, xedist]Simulate waiting times for the next 60 eruptions:
times = RandomVariate[edist, 60];ListPlot[{times, {{1, m1}, {60, m1}}, {{1, m2}, {60, m2}}}, Joined -> {False, True, True}, Filling -> {1 -> Axis}, AxesOrigin -> {0, 40}]Stock Price Distribution (1)
Lognormal distribution can be used to model stock prices:
stocks = FinancialData["SBUX", {{2010, 1, 1}, {2014, 1, 1}, "Day"}, "Value"];Fit the distribution to the data:
edist = EstimatedDistribution[stocks, LogNormalDistribution[μ, σ]]Observe that the quantiles for the data and distribution match well except for the largest values:
QuantilePlot[stocks, QuantityMagnitude[edist]]Water Flow Rates (1)
Consider the annual minimum daily flows given in cubic meters per second for the Mahanadi river:
minFlow = ExampleData[{"Statistics", "MahanadiRiverFlow"}];Model the annual minimum mean daily flows as a MinStableDistribution:
edist = EstimatedDistribution[minFlow, MinStableDistribution[a, b, c]]Compare the histogram of the data to the PDF of the estimated distribution:
Show[Histogram[minFlow, 10, "ProbabilityDensity"], Plot[PDF[edist, x], {x, 0, 7}, PlotStyle -> Thick]]Simulate annual minimum mean daily flows for the next 30 years:
ListLinePlot[RandomVariate[edist, 30]]Population Sizes (1)
Use a Pareto distribution to model Australian city population sizes:
cities = CityData[{All, "Australia"}];populations = QuantityMagnitude[CityData[#, "Population"]& /@ cities];edist = EstimatedDistribution[populations, ParetoDistribution[k, α, γ, μ]]Estimate the probability that a city has a population of at least 10,000 people:
Probability[x ≥ 10000, xedist]Compute the probability based on the original data:
Probability[x ≥ 10000, xpopulations]//NProperties & Relations (8)
EstimatedDistribution gives a distribution with parameter estimates inserted:
EstimatedDistribution[{5, 8, 3, 4, 9, 6}, PoissonDistribution[μ]]FindDistributionParameters gives parameter estimates as replacement rules:
FindDistributionParameters[{5, 8, 3, 4, 9, 6}, PoissonDistribution[μ]]EstimatedProcess estimates a parametric process:
data = RandomFunction[BernoulliProcess[0.4], {0, 10 ^ 5}];EstimatedProcess[data, BernoulliProcess[p]]EstimatedDistribution estimates a parametric distribution:
data = RandomVariate[BernoulliDistribution[0.4], 10 ^ 5];EstimatedDistribution[data, BernoulliDistribution[p]]Estimate distribution parameters by maximum likelihood:
data = RandomVariate[ExponentialDistribution[3], 1000];EstimatedDistribution[data, ExponentialDistribution[λ]]Use DistributionFitTest to test the quality of the fit:
ℋ = DistributionFitTest[data, ExponentialDistribution[λ], "HypothesisTestData"]Extract the fitted distribution:
ℋ["FittedDistribution"]Obtain a table of relevant test statistics and ![]() ‐values:
‐values:
ℋ[{"TestDataTable", All}]EstimatedDistribution estimates parameters in a parametric distribution:
data = RandomVariate[NormalDistribution[0, 1], 50];edist = EstimatedDistribution[data, NormalDistribution[μ, σ]]SmoothKernelDistribution gives a nonparametric kernel density estimate:
skdist = SmoothKernelDistribution[data]Compare the PDFs for the nonparametric and parametric distributions:
Plot[{PDF[skdist, x], PDF[edist, x]}, {x, -3, 3}, PlotStyle -> Thick]Visualize the nonparametric density using SmoothHistogram:
SmoothHistogram[data, PlotStyle -> Thick]EstimatedDistribution gives a maximum likelihood estimate of parameters:
data = RandomVariate[GammaDistribution[4, 10], 25];edist = EstimatedDistribution[data, GammaDistribution[α, β]]Compute the likelihood using Likelihood:
Likelihood[edist, data]Compute the log‐likelihood using LogLikelihood:
LogLikelihood[edist, data]Estimate parameters by matching raw moments:
data = RandomVariate[BetaDistribution[2, 5], 100];edist = EstimatedDistribution[data, BetaDistribution[α, β], ParameterEstimator -> "MethodOfMoments"]Compute raw moments from the data using Moment:
{Moment[data, 1], Moment[data, 2]}Compute the same moments from the estimated distribution:
{Moment[edist, 1], Moment[edist, 2]}Estimate parameters for a Weibull distribution:
data = RandomVariate[WeibullDistribution[3, 15], 100];edist = EstimatedDistribution[data, WeibullDistribution[α, β]]Use QuantilePlot to visualize empirical quantiles versus fitted distribution quantiles:
QuantilePlot[data, edist]Obtain the same visualization when the estimation is done within QuantilePlot:
QuantilePlot[data, WeibullDistribution[α, β]]EstimatedDistribution ignores time stamps in TimeSeries and EventSeries:
ts = TemporalData[TimeSeries, {{{1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1,
0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0,
1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1}}, {{0, 99, 1}}, 1, {"Continuous", 1}, {"Discrete", 1}, 1,
{ResamplingMethod -> {"Interpolation", InterpolationOrder -> 1}}}, False, 10.1];EstimatedDistribution[ts, BernoulliDistribution[p]]EstimatedDistribution[ts["Values"], BernoulliDistribution[p]]For TemporalData, all the path structure is ignored:
td = TemporalData[«4»];EstimatedDistribution[td, NormalDistribution[a, b]]EstimatedDistribution[td["ValueList"]//Flatten, NormalDistribution[a, b]]Possible Issues (3)
Solutions of method of moment equations can give parameters that are not valid:
EstimatedDistribution[{10, 12, 8, 15}, BinomialDistribution[n, p], ParameterEstimator -> "MethodOfMoments"]DistributionParameterQ[%]For a continuous distribution:
data = RandomVariate[NormalDistribution[-1, .1], 10 ^ 3];EstimatedDistribution[data, NormalDistribution[m, m], ParameterEstimator -> "MethodOfMoments"]DistributionParameterQ[%]Good starting values may be needed to obtain a good solution:
data = {4.1, 5.8, 4.3, 5.6, 3.8, 2.5, 3.1, 5.3, 5.4, 3.3};EstimatedDistribution[data, RiceDistribution[.01, α, β], ParameterEstimator -> "MethodOfMoments"]EstimatedDistribution[data, RiceDistribution[.01, α, β], {{α, 4}, {β, .02}}, ParameterEstimator -> "MethodOfMoments"]Good starting values may also result in quicker results:
data = RandomVariate[DirichletDistribution[Range[25]], 10 ^ 4];EstimatedDistribution[data, DirichletDistribution[Array[g, 25]]]//TimingEstimatedDistribution[data, DirichletDistribution[Array[g, 25]], Transpose[{Array[g, 25], Range[25]}]]//TimingText
Wolfram Research (2010), EstimatedDistribution, Wolfram Language function, https://reference.wolfram.com/language/ref/EstimatedDistribution.html.
CMS
Wolfram Language. 2010. "EstimatedDistribution." Wolfram Language & System Documentation Center. Wolfram Research. https://reference.wolfram.com/language/ref/EstimatedDistribution.html.
APA
Wolfram Language. (2010). EstimatedDistribution. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/EstimatedDistribution.html