

MatrixNormalDistribution
MatrixNormalDistribution[Σrow,Σcol]
represents a zero mean matrix normal distribution with row covariance matrix Σrow and column covariance matrix Σcol.
MatrixNormalDistribution[μ,Σrow,Σcol]
represents a matrix normal distribution with mean matrix μ.
Details
- MatrixNormalDistribution is a distribution of μ+
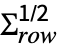 .x.
.x.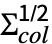 , where
, where 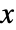 is a matrix with independent identically distributed matrix elements that follow NormalDistribution[0,1].
is a matrix with independent identically distributed matrix elements that follow NormalDistribution[0,1]. - The probability density for a matrix
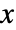 in a matrix normal distribution is proportional to
in a matrix normal distribution is proportional to 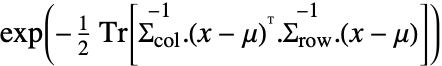 .
. - MatrixNormalDistribution[μ,c Σrow,c-1 Σcol] has the same distribution as MatrixNormalDistribution[μ,Σrow,Σcol] for any positive real constant c.
- The covariance matrices Σrow and Σcol can be any symmetric positive definite matrices of real numbers of dimensions {n,n} and {m,m}, respectively, and the mean matrix μ can be any matrix of real numbers of dimensions {n,m}.
- MatrixNormalDistribution can be used with such functions as MatrixPropertyDistribution, EstimatedDistribution, and RandomVariate.
Examples
open all close allBasic Examples (2)
Sample from a matrix normal distribution:
RandomVariate[MatrixNormalDistribution[{{3, 1, 1}, {1, 2, -1}, {1, -1, 4}}, {{1, -1 / 2}, {-1 / 2, 2}}]]Mean[MatrixNormalDistribution[{{1, 4}, {6, 8}, {10, 2}}, DiagonalMatrix[{2, 1, 3}], {{2, 1}, {1, 3}}]]//MatrixFormVariance[MatrixNormalDistribution[{{1, 4}, {6, 8}, {10, 2}}, DiagonalMatrix[{2, 1, 3}], {{2, 1}, {1, 3}}]]//MatrixFormScope (7)
Generate a single pseudorandom matrix:
RandomVariate[MatrixNormalDistribution[{{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3]]]Generate a single pseudorandom matrix with nonzero mean:
RandomVariate[MatrixNormalDistribution[{{1, 2, 3}, {4, 5, 6}}, {{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3]]]Generate a set of pseudorandom matrices:
RandomVariate[MatrixNormalDistribution[{{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3]], 3]RandomVariate[MatrixNormalDistribution[{{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3]], WorkingPrecision -> 20]Distribution parameters estimation:
dist = MatrixNormalDistribution[{{3, 1}, {1, 2}}, ToeplitzMatrix[{4, 2, 1}]];sample = RandomVariate[dist, 10 ^ 3];Estimate the distribution parameters from sample data:
edist = EstimatedDistribution[sample, MatrixNormalDistribution[Array[row, {2, 2}], Array[col, {3, 3}]]]Compare LogLikelihood for both distributions:
LogLikelihood[#, sample]& /@ {edist, dist}Find the probability that the smallest eigenvalue ![]() :
:
NProbability[λmin > 0.1, λminMatrixPropertyDistribution[Min[Abs[Eigenvalues[m]]], mMatrixNormalDistribution[IdentityMatrix[10], IdentityMatrix[10]]]]dist = MatrixNormalDistribution[IdentityMatrix[2], DiagonalMatrix[{2, 1}]];PDF[dist, {{1., 2.}, {3, 4.}}]Plot PDF for a diagonal matrices:
Plot3D[PDF[dist, DiagonalMatrix[{a, b}]], {a, -3, 3}, {b, -3, 3}]Skewness[MatrixNormalDistribution[{{2, 1}, {1, 3}}, IdentityMatrix[3]]]//MatrixFormKurtosis[MatrixNormalDistribution[{{2, 1}, {1, 3}}, IdentityMatrix[3]]]//MatrixFormApplications (2)
Visualize sample matrices from matrix normal distributions:
sigR = Covariance[ARProcess[{-0.95}, 1][Range[0, 100]]];
sigC = KroneckerProduct[IdentityMatrix[100, SparseArray], {{1, 1 / 2}, {1 / 2, 3}}];
vals = RandomVariate[MatrixNormalDistribution[sigR, sigC]];MatrixPlot[vals, PlotTheme -> "Minimal"]sigR = Covariance[ARProcess[{0.95}, 1][Range[0, 100]]];
sigC = KroneckerProduct[IdentityMatrix[100, SparseArray], {{1, 1 / 2}, {1 / 2, 3}}];
vals = RandomVariate[MatrixNormalDistribution[sigR, sigC]];MatrixPlot[vals, PlotTheme -> "Minimal"]Use a matrix normal distribution to simulate a vector autoregressive process:
sigR = Covariance[ARProcess[{a}, 1][Range[0, 100]]];
sigC = {{s11, s12}, {s12, s22}};rules = {a -> 1 / 2, s11 -> 1, s12 -> 1 / 2, s22 -> 3};dist = MatrixNormalDistribution[sigR, sigC] /. rules;vals = RandomVariate[dist, 10000];Construct TemporalData from sampled values:
td = TemporalData[vals, {0, Length[sigR] - 1, 1}, ValueDimensions -> 2];Estimate the diagonal vector autoregressive process:
proc = ARProcess[{a IdentityMatrix[2]}, {{s11, s12}, {s12, s22}}];sol = FindProcessParameters[td, proc]Compare to the original values:
sol[[All, 2]] - rules[[All, 2]]Properties & Relations (6)
A matrix normal distribution is defined up to a positive multiplicative constant:
sigr = {{2, 1}, {1, 4}};
sigc = ToeplitzMatrix[{9, 3, 1}];
𝒟1 = MatrixNormalDistribution[sigr, sigc];Equivalent distribution with row and column scale matrices multiplied and divided by a positive constant:
c = 2;
𝒟2 = MatrixNormalDistribution[c * sigr, sigc / c];Compute the PDF of the distributions at a random point:
mat = RandomReal[{-10, 10}, {2, 3}]PDF[𝒟1, mat] == PDF[𝒟2, mat]MatrixTDistribution[Σrow,Σcol,ν] is a parameter mixture of MatrixNormalDistribution[Σ,Σcol] with ![]() following InverseWishartMatrixDistribution[ν+n-1,Σrow]:
following InverseWishartMatrixDistribution[ν+n-1,Σrow]:
ν = 5;
n = 3;
Σr = IdentityMatrix[n];
Σc = IdentityMatrix[2];
invW = InverseWishartMatrixDistribution[ν + n - 1, Σr];Create a sample following the parameter mixture of MatrixNormalDistribution with InverseWishartMatrixDistribution:
sampleSize = 10 ^ 3;
sigmas = RandomVariate[invW, 10 ^ 3];
sample = Table[RandomVariate[MatrixNormalDistribution[s, Σc]], {s, sigmas}];Fit the sample data to MatrixTDistribution:
edist = EstimatedDistribution[sample, MatrixTDistribution[Array[s1, {3, 3}], Array[s2, {2, 2}], nu]]Compute log-likelihood ratio statistic against the appropriate MatrixTDistribution:
ratio = LogLikelihood[edist, sample] - LogLikelihood[MatrixTDistribution[Σr, Σc, ν], sample]Log-likelihood ratio follows ChiSquareDistribution with the parameter equal to the number of degrees of freedom:
dof = (Length[Σr] + 1) * Length[Σr] / 2 + (Length[Σc] + 1) * Length[Σc] / 2 + 1Compute the ![]() -value of log-likelihood ratio test:
-value of log-likelihood ratio test:
pval = SurvivalFunction[ChiSquareDistribution[dof], 2ratio]Sample from a matrix normal distribution with independent rows:
mat = RandomVariate[MatrixNormalDistribution[IdentityMatrix[10 ^ 3, SparseArray], {{1, -1 / 2}, {-1 / 2, 2}}]];Test the hypothesis that rows follow a multinormal distribution with the column covariance matrix:
BaringhausHenzeTest[mat, MultinormalDistribution[{0, 0}, {{1, -1 / 2}, {-1 / 2, 2}}], "TestConclusion"]Sample from a matrix normal distribution with independent rows:
mat = RandomVariate[MatrixNormalDistribution[IdentityMatrix[10 ^ 3, SparseArray], {{1, -1 / 2}, {-1 / 2, 2}}]];Test the hypothesis that rows follow a multinormal distribution with the column covariance matrix:
BaringhausHenzeTest[mat, MultinormalDistribution[{0, 0}, {{1, -1 / 2}, {-1 / 2, 2}}], "TestConclusion"]Sample from a matrix normal distribution with independent rows:
data = RandomVariate[MatrixNormalDistribution[IdentityMatrix[3], {{1, -1 / 2}, {-1 / 2, 2}}], 10 ^ 5];Computing sample inter-row covariances shows different rows are pairwise independent:
Round[Table[Covariance[data[[All, i]], data[[All, j]]], {i, 3}, {j, 3}], 0.05]//MatrixFormComputing sample inter-column covariances shows different columns are dependent:
Round[Table[Covariance[data[[All, All, i]], data[[All, All, j]]], {i, 2}, {j, 2}], 0.05]//MatrixFormBy joining the rows of the matrix-valued random variable together, a matrix normal distribution can be regarded as a multivariate normal distribution:
Subscript[Σ, r] = {{2, 1}, {1, 3}};
Subscript[Σ, c] = {{1, 1 / 2}, {1 / 2, 3}};mats = RandomVariate[MatrixNormalDistribution[Subscript[Σ, r], Subscript[Σ, c]], 5000];vecs = Flatten[mats, {{1}, {2, 3}}];The covariance matrix of the vectorized random matrix is the Kronecker product of ![]() and
and ![]() :
:
DistributionFitTest[vecs, MultinormalDistribution[{0, 0, 0, 0}, KroneckerProduct[Subscript[Σ, r], Subscript[Σ, c]]], {"TestDataTable", All}]Possible Issues (1)
A matrix normal distribution is defined up to a multiplicative scaling constant. The estimated parameters may not be close to the ones that specify the underlying distribution:
sigr = ToeplitzMatrix[{4, 2, 1}];
sigc = DiagonalMatrix[{3, 1}];
dist = MatrixNormalDistribution[sigr, sigc];Sample from the matrix normal distribution:
sample = RandomVariate[dist, 10 ^ 4];edist = EstimatedDistribution[sample, MatrixNormalDistribution[Array[s1, {3, 3}], Array[s2, {2, 2}]]];Compare the estimated scale parameters with the ones of the underlying distribution:
MatrixForm /@ {esigr = First[edist], sigr}MatrixForm /@ {esigc = edist[[2]], sigc}Kronecker products of the scale matrices are close to each other:
NumberForm[KroneckerProduct[sigr, sigc] - KroneckerProduct[esigr, esigc]//MatrixForm, 4]The LogLikelihood of the distribution indicates that the estimate is good:
LogLikelihood[#, sample]& /@ {dist, edist}Text
Wolfram Research (2015), MatrixNormalDistribution, Wolfram Language function, https://reference.wolfram.com/language/ref/MatrixNormalDistribution.html (updated 2017).
CMS
Wolfram Language. 2015. "MatrixNormalDistribution." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2017. https://reference.wolfram.com/language/ref/MatrixNormalDistribution.html.
APA
Wolfram Language. (2015). MatrixNormalDistribution. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/MatrixNormalDistribution.html