MatrixTDistribution[Σrow,Σcol,ν]
represents zero mean matrix ![]() distribution with row covariance matrix Σrow, column covariance matrix Σcol, and degrees of freedom parameter ν.
distribution with row covariance matrix Σrow, column covariance matrix Σcol, and degrees of freedom parameter ν.
MatrixTDistribution[μ,Σrow,Σcol,ν]
represents matrix ![]() distribution with mean matrix μ.
distribution with mean matrix μ.


MatrixTDistribution
MatrixTDistribution[Σrow,Σcol,ν]
represents zero mean matrix ![]() distribution with row covariance matrix Σrow, column covariance matrix Σcol, and degrees of freedom parameter ν.
distribution with row covariance matrix Σrow, column covariance matrix Σcol, and degrees of freedom parameter ν.
MatrixTDistribution[μ,Σrow,Σcol,ν]
represents matrix ![]() distribution with mean matrix μ.
distribution with mean matrix μ.
Details
- The probability density for a matrix
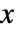 of dimensions
of dimensions 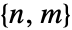 in a matrix
in a matrix 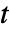 distribution is proportional to
distribution is proportional to 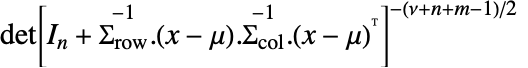 with
with 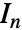 an identity matrix of length
an identity matrix of length 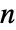 .
. - MatrixTDistribution[Σrow,Σcol,ν] is the distribution of MatrixNormalDistribution[Σ,Σcol] with
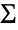 sampled from InverseWishartMatrixDistribution[ν+n-1,Σrow].
sampled from InverseWishartMatrixDistribution[ν+n-1,Σrow]. - MatrixTDistribution[μ,c Σrow,c-1 Σcol,ν] has the same distribution as MatrixTDistribution[μ,Σrow,Σcol,ν] for any positive real constant c.
- The covariance matrices Σrow and Σcol can be any symmetric positive definite matrices of real numbers of dimensions {n,n} and {m,m}, respectively. The degrees of freedom parameter ν can be any positive number, and the mean matrix μ can be any matrix of real numbers of dimensions {n,m}.
- MatrixTDistribution can be used with such functions as MatrixPropertyDistribution, EstimatedDistribution, and RandomVariate.
Examples
open all close allBasic Examples (2)
Sample from matrix ![]() distribution:
distribution:
sigR = {{3, 1}, {1, 4}};
sigC = {{1, -1 / 2}, {-1 / 2, 2}};RandomVariate[MatrixTDistribution[sigR, sigC, 3]]Mean[MatrixTDistribution[{{1, 2}, {3, 4}, {5, 6}}, DiagonalMatrix[{2, 1, 3}], {{2, 1}, {1, 3}}, 4]]//MatrixFormVariance[MatrixTDistribution[{{1, 2}, {3, 4}, {5, 6}}, DiagonalMatrix[{2, 1, 3}], {{2, 1}, {1, 3}}, 4]]//MatrixFormScope (6)
Generate a single pseudorandom matrix:
RandomVariate[MatrixTDistribution[{{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3], 2]]Generate a single pseudorandom matrix with nonzero mean:
RandomVariate[MatrixTDistribution[{{1, 2, 3}, {4, 5, 6}}, {{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3], 2]]Generate a set of pseudorandom matrices:
RandomVariate[MatrixTDistribution[{{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3], 2], 3]RandomVariate[MatrixTDistribution[{{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3], 2], WorkingPrecision -> 20]RandomVariate[MatrixTDistribution[{{1, 2, 3}, {4, 5, 6}}, {{1, 1 / 3}, {1 / 3, 1}}, IdentityMatrix[3], 2], WorkingPrecision -> 20]Distribution parameters estimation:
dist = MatrixTDistribution[{{3, 1}, {1, 2}}, ToeplitzMatrix[{4, 2, 1}], 4];sample = RandomVariate[dist, 10 ^ 3];Estimate the distribution parameters from sample data:
edist = EstimatedDistribution[sample, MatrixTDistribution[Array[row, {2, 2}], Array[col, {3, 3}], ν]]Compare LogLikelihood for both distributions:
LogLikelihood[#, sample]& /@ {edist, dist}Skewness[MatrixTDistribution[{{2, 1}, {1, 3}}, IdentityMatrix[3], 5]]//MatrixFormKurtosis[MatrixTDistribution[{{2, 1}, {1, 3}}, IdentityMatrix[3], 5]]//MatrixFormdist = MatrixTDistribution[IdentityMatrix[2], DiagonalMatrix[{2, 1}], 3];PDF[dist, {{1., 2.}, {3, 4.}}]Plot PDF for a diagonal matrices:
Plot3D[PDF[dist, DiagonalMatrix[{a, b}]], {a, -2, 2}, {b, -1, 1}]Properties & Relations (4)
Matrix t distribution is defined up to a positive multiplicative constant:
sigr = {{2, 1}, {1, 4}};
sigc = ToeplitzMatrix[{9, 3, 1}];
𝒟1 = MatrixTDistribution[sigr, sigc, 3];Equivalent distribution with row and column scale matrices multiplied and divided by a positive constant:
c = 2;
𝒟2 = MatrixTDistribution[c * sigr, sigc / c, 3];Compute the PDF of the distributions at a random point:
mat = RandomReal[{-10, 10}, {2, 3}]PDF[𝒟1, mat] == PDF[𝒟2, mat]MatrixTDistribution[Σrow,Σcol,ν] is a parameter mixture of MatrixNormalDistribution[Σ,Σcol] with ![]() following InverseWishartMatrixDistribution[ν+n-1,Σrow]:
following InverseWishartMatrixDistribution[ν+n-1,Σrow]:
ν = 3;
n = 2;
Σr = IdentityMatrix[n];
Σc = IdentityMatrix[3];
invW = InverseWishartMatrixDistribution[ν + n - 1, Σr];Create a sample following the parameter mixture of MatrixNormalDistribution with InverseWishartMatrixDistribution:
sampleSize = 10 ^ 3;
sigmas = RandomVariate[invW, 10 ^ 3];
sample = Table[RandomVariate[MatrixNormalDistribution[s, Σc]], {s, sigmas}];Fit the sample data to MatrixTDistribution:
edist = EstimatedDistribution[sample, MatrixTDistribution[Array[s1, {2, 2}], Array[s2, {3, 3}], nu]]Compute log-likelihood ratio statistic against the appropriate MatrixTDistribution
ratio = LogLikelihood[edist, sample] - LogLikelihood[MatrixTDistribution[Σr, Σc, ν], sample]Log-likelihood ratio follows ChiSquareDistribution with the parameter equal to the number of degrees of freedom:
dof = (Length[Σr] + 1) * Length[Σr] / 2 + (Length[Σc] + 1) * Length[Σc] / 2 + 1Compute the ![]() -value of log-likelihood ratio test:
-value of log-likelihood ratio test:
pval = SurvivalFunction[ChiSquareDistribution[dof], 2ratio]For matrix ![]() sampled from matrix
sampled from matrix ![]() distribution, the expression
distribution, the expression ![]() follows Student
follows Student ![]() distribution for any nonzero vectors
distribution for any nonzero vectors ![]() and
and ![]() with lengths that match with the dimension of
with lengths that match with the dimension of ![]() :
:
v1 = RandomReal[1, 2];v2 = RandomReal[1, 3];Use MatrixPropertyDistribution to sample values of the expression ![]() :
:
Subscript[Σ, r] = {{1, 4 / 5}, {4 / 5, 1}};Subscript[Σ, c] = {{2, 1, 0}, {1, 3, 1}, {0, 1, 2}};df = 5;data = RandomVariate[MatrixPropertyDistribution[v1.𝓂.v2, 𝓂MatrixTDistribution[Subscript[Σ, r], Subscript[Σ, c], df]], 10 ^ 4];Check agreement with the expected ![]() distribution:
distribution:
t𝒟 = StudentTDistribution[0, Sqrt[(v1.Subscript[Σ, r].v1)(v2.Subscript[Σ, c].v2) / df], df];DistributionFitTest[data, t𝒟]Show[Histogram[data, Automatic, PDF], Plot[PDF[t𝒟, x], {x, -4, 4}, PlotRange -> All]]For matrix ![]() sampled from matrix
sampled from matrix ![]() distribution,
distribution, ![]() follows multivariate
follows multivariate ![]() distribution for any nonzero vector
distribution for any nonzero vector ![]() with length that matches with the number of columns of
with length that matches with the number of columns of ![]() :
:
v = RandomReal[1, 3];Use MatrixPropertyDistribution to sample values of ![]() :
:
Subscript[Σ, r] = {{1, 4 / 5}, {4 / 5, 1}};Subscript[Σ, c] = {{2, 1, 0}, {1, 3, 1}, {0, 1, 2}};df = 5;data = RandomVariate[MatrixPropertyDistribution[𝓂.v, 𝓂MatrixTDistribution[Subscript[Σ, r], Subscript[Σ, c], df]], 10 ^ 4];Verify goodness of fit with the expected distribution:
DistributionFitTest[data, MultivariateTDistribution[Subscript[Σ, r] (v.Subscript[Σ, c].v) / df, df]]Possible Issues (1)
Matrix ![]() distribution is defined up to a multiplicative scaling constant. The estimated parameters may not be close to the ones that specify the underlying distribution:
distribution is defined up to a multiplicative scaling constant. The estimated parameters may not be close to the ones that specify the underlying distribution:
ν = 4;
sigr = ToeplitzMatrix[{9, 3, 1}];
sigc = DiagonalMatrix[{1, 2}];
dist = MatrixTDistribution[sigr, sigc, ν];Sample from the matrix ![]() distribution:
distribution:
sample = RandomVariate[dist, 10 ^ 4];edist = EstimatedDistribution[sample, MatrixTDistribution[Array[s1, {3, 3}], Array[s2, {2, 2}], ν]];Compare the estimated scale parameters with the ones of the underlying distribution:
MatrixForm /@ {esigr = First[edist], sigr}MatrixForm /@ {esigc = edist[[2]], sigc}Kronecker products of the scale matrices are close to each other:
NumberForm[KroneckerProduct[sigr, sigc] - KroneckerProduct[esigr, esigc]//MatrixForm, 4]The LogLikelihood of the distributions indicate that the estimate is good:
LogLikelihood[#, sample]& /@ {dist, edist}Text
Wolfram Research (2015), MatrixTDistribution, Wolfram Language function, https://reference.wolfram.com/language/ref/MatrixTDistribution.html (updated 2017).
CMS
Wolfram Language. 2015. "MatrixTDistribution." Wolfram Language & System Documentation Center. Wolfram Research. Last Modified 2017. https://reference.wolfram.com/language/ref/MatrixTDistribution.html.
APA
Wolfram Language. (2015). MatrixTDistribution. Wolfram Language & System Documentation Center. Retrieved from https://reference.wolfram.com/language/ref/MatrixTDistribution.html